Selenium is the most popular and widely-used open source collection of automation tools and libraries which enables and supports automation of web browsers. Selenium is primarily used for testing Web User Interfaces but it is not limited to just that. A wide range of activities related to browsers can also be done with the help of Selenium.
Selenium supports automation across different browsers, platforms and programming languages, making it the most preferred automation tool in the testing community. It provides extensions to emulate user interaction with browsers, a distribution proxy server for scaling browser allocation and the infrastructure to implement the W3C WebDriver specification (www.w3.org/TR/webdriver/) that lets us write interchangeable code for all the major web browsers like Chrome, Firefox, Internet Explorer, MS Edge, Safari, Opera and HTMLUnit.
It works on multiple Operating Systems like Windows, macOS and Linux as well as with multiple Programming Languages like Java, Python, C#, Ruby, JavaScript, Perl and PHP.
As told earlier, Selenium is not just a single tool but it comprises of many tools/ APIs namely:
– Selenium WebDriver
– Selenium Remote Control
– Selenium IDE
– Selenium Grid
– Selenium HTML Runner
At the core of Selenium is the “WebDriver” (Selenium2, Selenium3) which is an interface that uses browser automation APIs provided by the browser vendors to control the browsers and to write instruction code that can be run interchangeably in all the browsers mentioned above.
“Selenium Remote Control (RC)” (Selenium1) is basically a HTTP Proxy Server which injects JavaScript into a browser to automate the actions. Selenium2 APIs still contain the Selenium RC APIs but Selenium3 and the subsequent versions of Selenium would not have Selenium RC APIs at all. So preferably you should not use it.
“Selenium IDE” is essentially a Mozilla Firefox browser plugin which can be used to record the automation steps in the Firefox browser and generate codes in C#, Java, Python and Ruby. Preferably you should use Selenium WebDriver to automate your tests with the help of writing good locator and action codes which we will be discussing later in this tutorial. For quick prototyping of your Selenium tests you can use Selenium IDE.
“Selenium Grid” is a Selenium API which can be used to run automation tests on multiple browsers and operating systems. It is technically a proxy server that allows Selenium tests to route commands to remote web browser instances to provide an easy way to run tests in parallel on multiple machines. We will discuss Selenium Grid in detail at a later point in this tutorial.
“Selenium HTML Runner” allows us to run an automation Test Suite (not Test Case) from a command line. The automation tests are HTML exports from Selenium IDE or other compatible tools.
INTRODUCTION
Most of the software applications built today are written to run as web applications in the browsers. In this age of highly interactive and responsive software processes where many organizations are using some form of Agile methodology, using automated checks in Testing is becoming a must-requirement for them. Selenium is possibly the most widely-used open source solution to perform automation testing of the web-based applications. Although used primarily for UI testing, Selenium at its core is browser user-agent library.
As told earlier, Selenium is a collection of many things but at its core it is a collection of tools for web browser automation that uses the best techniques available to remote control browser instances and emulate a user’s interaction with the browser. It allows users to simulate actions performed by end-users like clicking on a button, entering text into text fields, selecting drop-down values, checking or unchecking checkboxes, clicking links etc. It also provides automation of other actions like hovering over an element, mouse movement, javascript execution etc.
SELENIUM HISTORY
Selenium was born in 2004 when Jason Huggins was testing an internal application at Thoughtworks. He created a JavaScript library that could drive interactions with the webpage, allowing him to automatically run tests against multiple browsers. It was out of necessity to reduce time spent manually verifying consistent behavior in the front-end of the web application. While JavaScript is a good tool to let you inspect the DOM properties and perform certain client-side observations that you would otherwise not be able to do, it falls short on the ability to naturally replicate a user’s interactions.
Since then, Selenium has grown and matured a lot with the introduction of Selenium IDE, Selenium RC, Selenium WebDriver and Selenium Grid. Selenium WebDriver has now become a World Wide Web Consortium (W3C) recommendation which means that it is now officially supported and endorsed by W3C. You can read about the detailed changes due to this from here.
SELENIUM FEATURES
Some of the key features of Selenium are mentioned below:
– Selenium is an Open Source project which means that it is free-to-use
– Selenium IDE has the ability to record and playback automation steps and generate codes in C#, Java, Python and Ruby
– Selenium Grid is used to run parallel tests on multiple machines having multiple browsers and multiple OS
– Selenium supports the following programming languages:
Java, Python, C#, Ruby, JavaScript
– Selenium can run on the following operating systems:
Windows, Linux, macOS, Android, iOS
– Selenium scripts can run on the following internet browsers:
Google Chrome, Mozilla Firefox, Internet Explorer, Microsoft Edge, Opera, Safari
– Selenium can be integrated with other tools/libraries/frameworks like TestNG, Junit, Maven, Gradle, Ant, Jenkins, Docker etc.
– Selenium WebDriver does not require server installation as it can interact directly with the browsers.
SELENIUM WEBDRIVER ARCHITECTURE
The Selenium WebDriver Architecture follows the popular Client-Server architecture and consists mainly of four components:
- Selenium Client and Language Bindings
- JSON Wire Protocol over HTTP
- Browser Drivers
- Web Browsers
Below diagram shows in detail the Selenium WebDriver Framework Architecture with its components:
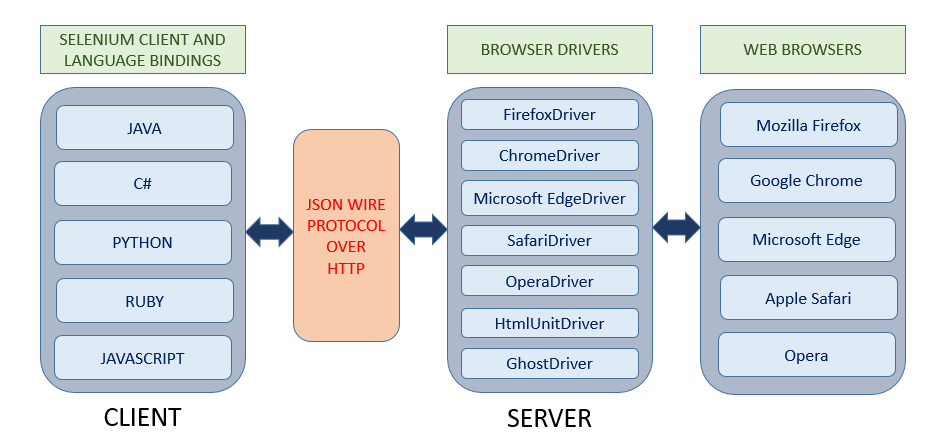
Selenium Client and Language Bindings
Selenium Client is responsible for sending out requests to perform Selenium WebDriver execution commands. The Selenium WebDriver bindings are code libraries developed and maintained by the developers of the Selenium project and are available in different programming languages namely Java, C#, Python, Ruby and JavaScript. Consider an example of opening a webpage using Java bindings in Selenium. The same operation of opening the webpage can also be performed using Selenium bindings of the other languages like C#, Python, Ruby and JavaScript.
JSON Wire Protocol over HTTP
All implementations of the Selenium WebDriver that communicate with the browser drivers use a common wire HTTP (Hyper Text Transfer Protocol) protocol. This wire protocol defines a RESTful Web Service using JSON (JavaScript Object Notation) over HTTP and is commonly known as JSON Wire Protocol. This JSON Wire Protocol is implemented in request/response pairs of “commands” and “responses”. The JSON wire protocol makes API calls for every Selenium command coming from the Selenium WebDriver API.
Browser Drivers
The browser drivers are servers that implement the JSON wire protocol and they know how to convert the Selenium commands into specific browser’s proprietary native APIs without revealing the internal logic of browser’s functionality. The browser drivers which are used along with the Selenium client libraries are ChromeDriver, FirefoxDriver, EdgeDriver, SafariDriver, OperaDriver, HTMLUnitDriver and GhostDriver. The browser drivers act as servers and receive HTTP requests from the selenium client in the form of URLs and send HTTP responses back to them thereby implementing the Client-Server architecture through the JSON Wire Protocol.
Web Browsers
The web browsers are software programs that allow users to locate, access and display web pages as well as other contents created using HTML (Hyper Text Markup Language) and XML (Extensible Markup Language) languages. All the executions of the Selenium commands are performed in the Web Browsers (Chrome, Firefox, Edge, Safari, Opera and Internet Explorer) through their respective browser drivers which act as middlemen.
Let’s now understand the flow through an example.
Suppose you write the below Selenium code (using its Java binding) in an IDE (Integrated Development Environment) of your choice.
WebDriver driver=new ChromeDriver();
driver.get(“https://www.google.com”);Once you run this code, Chrome browser will get launched and you will be navigated to the home page of google. Internally, what happens is that – Every statement of the code gets converted to an URL with the help of JSON Wire Protocol over HTTP. The URLs are then passed to the Browser Drivers. In the above case, the Java client library will convert the Java code statements to JSON format and communicate with the “ChromeDriver” browser driver executable file. The URL will look like below:
http://localhost:8080/{“url”:”https://www.google.com”}Every browser driver uses a HTTP server to receive the HTTP requests. Once the URL reaches the browser driver, then the browser driver will pass that request to the respective web browser over HTTP and the selenium commands will get executed on the browser. For an HTTP POST request, there will be an action on the browser and for an HTTP GET request, the response will get generated at the browser end and will be sent over HTTP to the browser driver. The browser driver will then send the response to the IDE via the JSON Wire Protocol.
INSTALLATION
Setting up Selenium WebDriver in your machine and running your tests using Selenium is pretty simple. We will go through each step one by one in Windows machine and ensure that you are able to run your first Selenium script (using Java programming language) without any roadblock.
1) Install Java and set Java Environment Variable Path
Java Development Kit (JDK) is an application to create and modify programs in Java. To install Java in your system, download JDK from Oracle JDK Downloads page. After download, go through the installation process and complete it. Once installation is complete, go to Environment Variables in your system and set up JAVA_HOME as system/user variable and include %JAVA_HOME%\bin in your path variable. To check whether Java has been successfully installed or not, open command prompt in your system, type java -version and press Enter. It should display the JDK version that your system is currently referring to.
2) Download Selenium Java Client Libraries and Browser Drivers
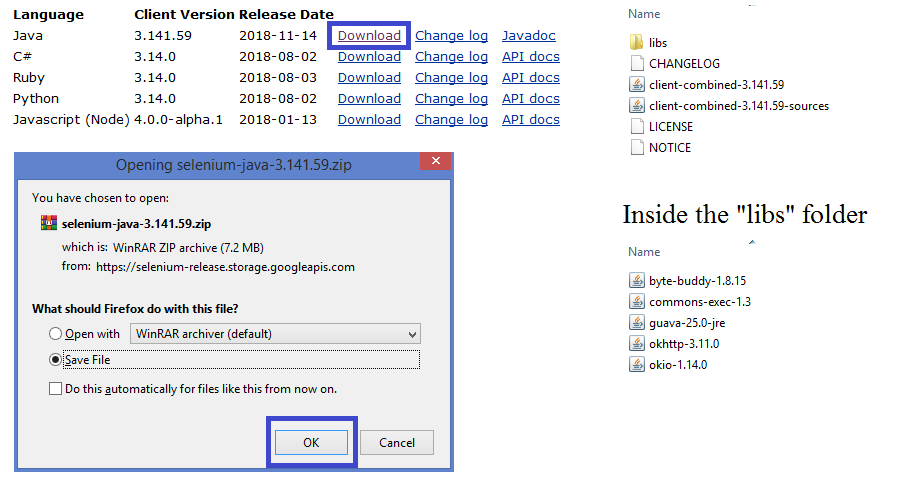
In this tutorial we will be running our Selenium tests using Java and hence we require to download the “Selenium Java Client Libraries”and “Browser Drivers” for respective browsers from the Selenium official download page.
To download the Selenium Java Client libraries, click on the “Download” link against “Java” (Figure below) and save the zip file in your file system of your machine. Extract the saved zip file and you will be able to see the jar files (shown in the figure below). Remember that some jar files will also be present inside the “libs” folder.
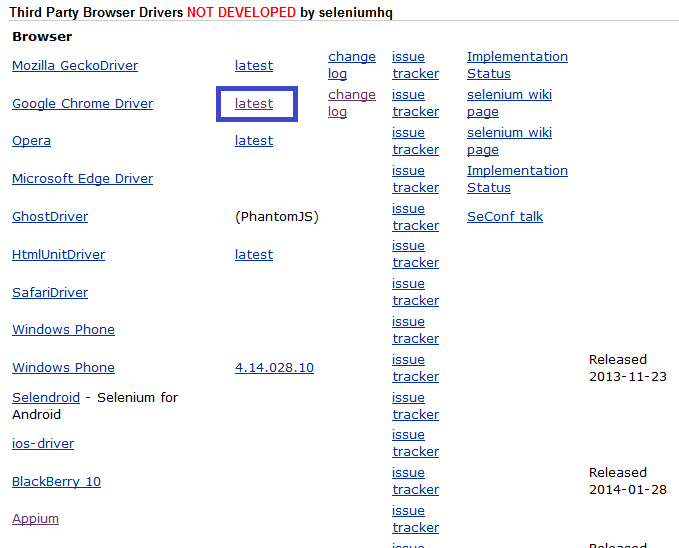
As discussed in the Introduction section, we also need to download the browser drivers for the browsers. For example, scroll down the webpage and you can click on the “latest” link against “Google Chrome Driver” to get redirected to the page from where you can download different browser drivers for different Google Chrome browser versions (Figure below). Choose the one according to the Chrome browser version in your system.
3) Download Eclipse IDE (or any Java IDE of your choice)
In this tutorial we will be using the popular “Eclipse IDE” to write and run our Selenium tests in Java language. You can use any other Java IDE of your choice like IntelliJ IDEA or NetBeans. To download Eclipse, go to the official Eclipse Foundation Page and download any one of the following Eclipse IDE packages:
– Eclipse Photon
– Eclipse Oxygen
– Eclipse Neon
– Eclipse Mars
– Eclipse Luna
Once downloaded, extract the zip file and click on “eclipse.exe” inside the eclipse folder to launch Eclipse IDE in your system.
4) Configuring Selenium in Eclipse
To configure Selenium in Eclipse and to run your first Selenium test, follow the below steps (Figures below):
– Open Eclipse
– Create a new Java Project
– Check the project is set to Java 1.8 or higher
– Add the Selenium JARs
To add the Selenium jars, follow the below steps after creating a “libs” folder under the “FirstSeleniumTest” project (Right click on FirstSeleniumTest -> Click New -> Click Folder -> Enter Folder Name “libs” -> Click Finish).
Copy all the earlier downloaded Selenium JARS from your local file system and paste inside this “libs” folder in Eclipse. Then, add the JARS inside the libs folder to the project classpath like below (Right click on FirstSeleniumTest -> Build Path -> Configure Build Path -> Add JARS -> Click Apply -> Click OK)
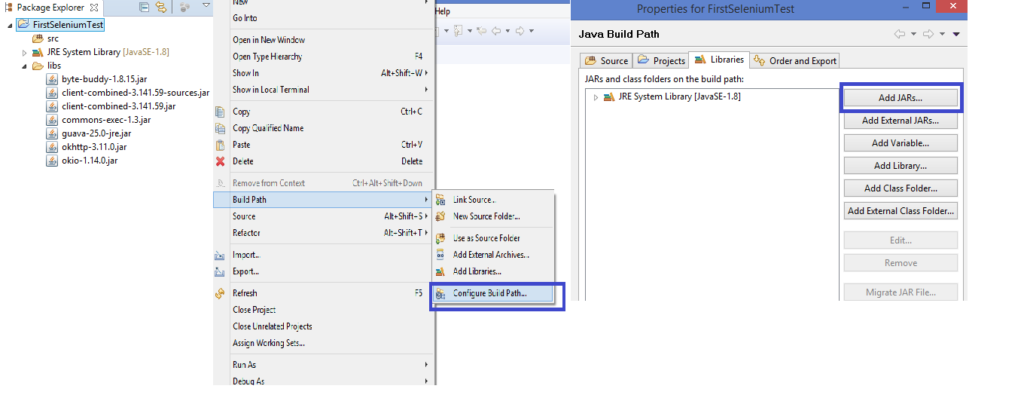
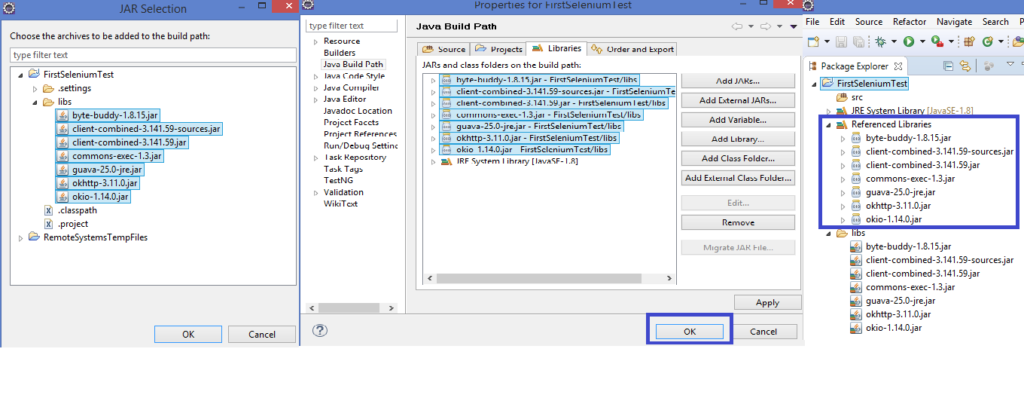
Congratulations!! You have successfully configured Selenium in your Java project in Eclipse and you are set to run your first Selenium test.
FIRST SELENIUM TEST
In this section of the Selenium tutorial we will learn to run our first test using the Selenium WebDriver API. But before running our first Selenium test, let’s first understand what Web Elements in a web browser are since all the web applications are made up of web elements. The success of automated UI tests depends on recognizing these elements efficiently to achieve the test flow.
The Web Elements or Web Browser Elements are the various webpage components which make up the webpage. Examples are:- Edit Box, Text Box, Link, Button, Image, Text Area, Radiobutton, Checkbox, Error and Notification message, Combobox, Dropdown, Tables, Frames, Forms and many more. Performing automated UI tests on these web elements essentially means whether they are working correctly or not. Consider an example where we are testing a “Button” web element – so we might be checking whether the button is in enabled or disabled condition or whether the innertext of the button is equal to the value that we are expecting or not. If the button is enabled, are we able to successfully click on it or not and once clicked, are the expected events happening or not. Thus, it is evident that to perform testing or checks using the web elements we basically need to perform two things:
1) Locate the web element on the webpage
2) Once located, perform actions/operations on that web element
BROWSER OPENING
But before starting to deal with the web elements, first we need to open the web browser and navigate to the webpage by providing the URL using WebDriver. Here, we will use the “Chrome” as browser and “ChromeDriver” as the browser driver server. In the FirstSeleniumTest java project that we created earlier in the Eclipse IDE, create a package with the name “tests” (Right click on FirstSeleniumTest -> New -> Package -> Name: tests -> Click Finish) and inside it create a class with the name “BasicTest” (Right click on src -> New -> Class -> Name: BasicTest -> Check the “public static void main” checkbox -> Click Finish). N.B:- You can give any name of your choice to the package and the class.
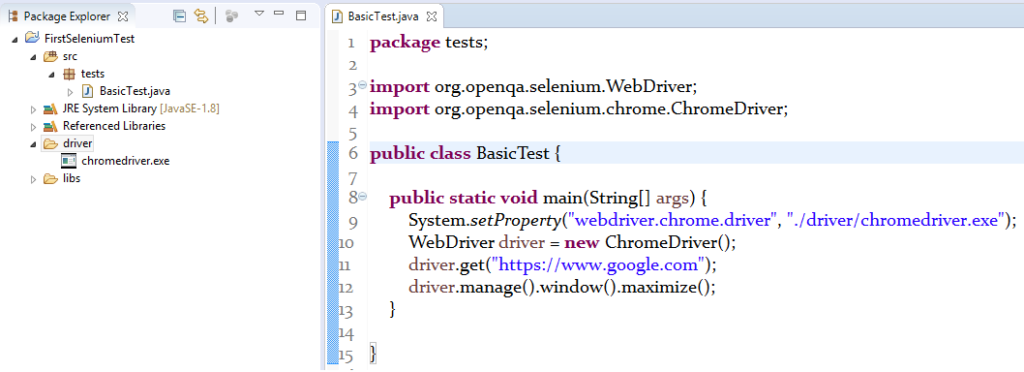
Now create a folder named “driver” inside the FirstSeleniumTest project and put the downloaded “chromedriver.exe” file which is the chrome browser driver. Now write the below code inside the BasicTest class and run it (Right click inside the class -> Run As -> Java Application)
package tests;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class BasicTest {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "./driver/chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get("https://www.google.com");
driver.manage().window().maximize();
}
}Once you run the code, you will notice that Chrome browser will get invoked and launched automatically and the google home page will open up. The browser window will then get maximized and the execution in Eclipse will get stopped.
In the statement “import org.openqa.selenium.WebDriver;”, org.openqa.selenium is a library package which contains the WebDriver interface which in turn extends the SearchContext interface(the super most interface in Selenium). The RemoteWebDriver class implements the abstract methods of both these interfaces in addition to some extra interfaces like JavascriptExecutor, HasCapabilites, Interactive and TakesScreenshot imterface.
In the statement “import org.openqa.selenium.chrome.ChromeDriver;”, org.openqa.selenium.chrome is a library package which contains the ChromeDriver class(a subclass of the RemoteWebDriver class)needed to write tests against the Chrome browser. It is a WebDriver implementation that controls a Chrome browser running on the local machine. The control server which each Chrome instance communicates with will live and die with the instance.
In the statement
System.setProperty(“webdriver.chrome.driver”,”./driver/chromedriver.exe”);
the name of the system property (i.e. key) is set to “webdriver.chrome.driver”and the value of this system property is set to “./driver/chromedriver.exe” which is the path to the chromedriver.exe file. You can also provide the absolute path from file system here. This statement notifies the run-time engine that the chromedriver.exe file is present in the specified path (here it is inside the “driver” folder). For other browsers, we have to provide different key and value to this setProperty method. This statement is required because the browsers do not have built-in servers to run the code and hence the browser drivers are required to communicate the Selenium code to the browsers.
N.B: This line should be the first line in your Selenium code.
WebDriver driver = new ChromeDriver();
In this statement, an object of the ChromeDriver class is initiated by taking reference of the WebDriver interface and the reference variable’s name is given “driver”. Declaring in this way, we can use the same object to initiate other browsers (e.g. Firefox or IE) and call various implementations of the WebDriver interface methods in the implementing classes. Here, we can achieve Runtime Polymorphism which will help us to automate Selenium scripts in different browsers for Cross-Browser testing and switching will be easy.
driver.get(“https://www.google.com”);
This statement helps to navigate to the specified URL. Here the URL is https://www.google.com
driver.manage().window().maximize();
This statement maximizes the current browser window. It is a good practice to maximize the browser at the start while automating any web application in order to view all the visible web elements of the application.
LOCATING AND ACTIONS
LOCATING ELEMENTS
Selenium WebDriver API provides advanced techniques to locate the elements in webpages. In the previous section, we have already discussed about what web elements are. We also talked about the different web elements that we usually come across in the modern web applications. The WebDriver API itself provides multiple locator strategies and also we can create our own custom locator strategies as per our need. The main aim is to find the most reliable and stable locator for each element. One of the most important skills of a test automation engineer working with Selenium is to be able to use appropriate methods to locate the elements.
A “locator” tells what we want to find on a webpage. For Selenium Java bindings, we create a locator by using the “By” class which supports various locator strategies and WebDriver interface extends the “SearchContext” interface to locate elements on that page. The SearchContext interface consists of two abstract methods which take the instances of the By class as arguments:
List<WebElement> findElements(By var1);
WebElement findElement(By var1);The first method returns a list of all the WebElements matching the “By” instance (locator) passed into it as argument and if no matched element is found, the method returns an empty list. The second method helps us to find only the first element which matches the “By” instance (locator) passed into it as argument. If the element is not found, an object of the NoSuchElementException exception is thrown. Hence. locating elements is achieved by using this findElement() and findElements() methods provided by the WebDriver and the SearchContext interfaces.
We can find the elements by using the following locator techniques:
- By ID
- By Name
- By Class Name
- By Link Text
- By Partial Link Text
- By Tag Name
- By XPath
- By CSS Selector
For any web application, the UI developers use tags (e.g. a, td, tr, table, input, select, form etc.) and assign attribute values to the attributes (e.g id, name, class, text etc.) to create a web element in the html page. This makes the application more testable and conforms to accessibility standards. For cases where these attributes do not provide enough information to locate an element, the advanced locator strategies like XPath and CSS selector are used. While both CSS selector and XPath are popular among the automation testers, CSS selector is preferred to XPath due to its simplicity, speed and high performance.
How to find the element tags, attributes and the HTML page structure?
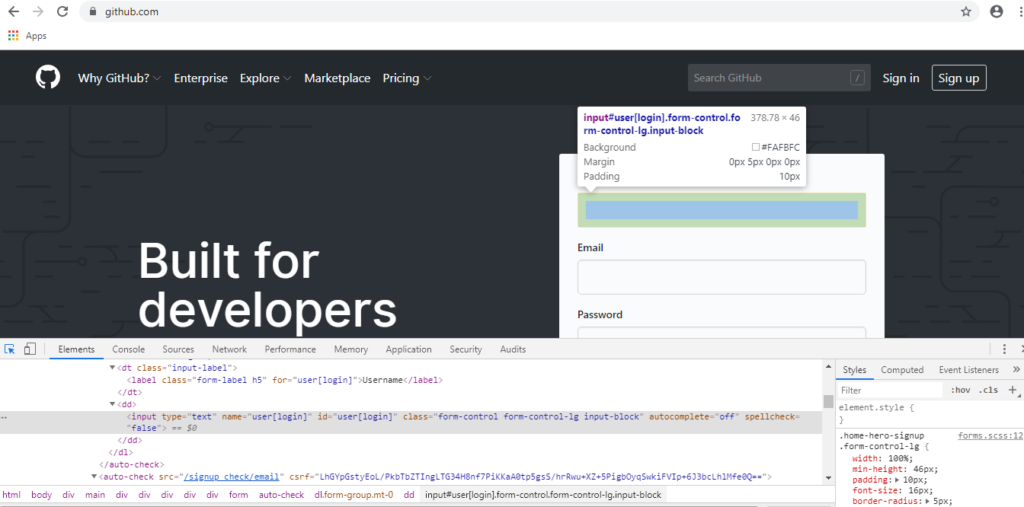
Before we start writing our locators, we first need to analyze the webpage and understand how the elements are structured in the application, their attribute and attribute values and how JavaScript/Ajax calls are made from the application. Since the web browsers hide the HTML code and render visual elements of the application, first we need to check how we can see the HTML code.
In Chrome, you can visualize the HTML code and the DOM (Document Object Model – the programming interface for HTML or XML documents) structure, JavaScript calls, CSS style attributes, Event listeners etc. in a separate window (Developer Tools window) if you right-click in the browser window and select the “Inspect” option from the pop-up menu or by simply pressing the F12 button. If you want to see the code for a particular element, then right click on that element and then select the “Inspect” option from the pop-up menu. Alternatively, you can press Ctrl+Shift+C and then put your cursor on that element. The respective HTML code for that element will get highlighted. In Firefox browser, the same thing can be achieved by selecting the “Inspect Element” option from the pop-up menu or by pressing F12 button.
By ID
Using the unique “ID” attribute is the most preferable way to locate web elements. Having a unique ID attribute provides a very explicit and reliable way to locate elements on the page. While processing the DOM, the browser engine uses ID as the preferred way to identify the elements and this provides the fastest locator strategy. Let’s now see how the id attribute of the GitHub landing page is laid out for the “Username” text field.
<dl class="form-group mt-0">
<dt class="input-label">
<label class="form-label h5" for="user[login]">Username</label>
</dt>
<dd>
<input type="text" name="user[login]" id="user[login]" class="form-control form-control-lg input-block">
</dd>
</dl>To locate the Username field, we can use the ID attribute in the following way:
WebElement userName = driver.findElement(By.id(“user[login]”));
By Name
It is as good as ID, but you won’t come across it as often as you’d expect. Elements from forms usually have the “name” attribute. We can use the name attribute to locate the Username field in the following way:
WebElement userName = driver.findElement(By.name(“user[login]”));
Unlike ID, the name attribute may not be unique on a page. There may be multiple elements with similar name attributes and in such cases, the first matched element with the specified name attribute value will be selected.
By Class Name
We can also use the class attribute and its value to locate elements. But it is not so reliable since the class name is usually shared by multiple elements on a webpage. The class name can be used in the following way:
WebElement username = driver.findElement(By.className(“form-control”));
The most common mistake done by the automation developers is they extract all the class names instead of just one. If we consider the username example:
<input type="text" name="user[login]" id="user[login]" class="form-control form-control-lg input-block">Here, actually there are 3 class names present separated by spaces and not one. The three class names are “form-control”, “form-control-lg” and “input-block”.
By Link Text
Selenium WebDriver provides multiple ways to locate links. We can locate a link by its text or partial text. Selenium WebDriver’s By class provides the linkText() method to locate links using the text displayed for the link. The linkText() method queries the webdriver for all the links that meet the specified text and returns the matching link(s) .For example, in the GitHub landing page if we want to locate the Terms of Service link given in the following format:
<a class="text-white" href="https://help.github.com/terms" target="_blank">terms of service</a>Then we can use the following statement:
WebElement termsOfServiceLink = driver.findElement(By.linkText(“Terms of Service”));
Also remember that the link text is only the text between the starting and the closing tags (<a> and </a>)
By Partial Link Text
Locating links with partial link text comes in handy when links have dynamic text. Here we can use the partialLinkText() method to locate the link using a fixed or known part of the link text. As the name suggests, it is exactly like link text but with the difference that we only need to add a fixed or known part of the link text.
WebElement termsOfServiceLink = driver.findElement(By.partialLinkText(“Terms of”));
By Tag Name
Selenium WebDriver’s By class provides a tagName() method to find elements by their HTML tag names. This comes in handy when we want to locate elements using their tag name. For example, locating all the buttons in a page using the <button> tag. An element always has a tag associated with it. We can use the Tag Name locator type if that is the only unique identifier of the element that we want to locate. In reality, we rarely use this locator technique to locate a particular element since there are often many repeating uses of most tags. But it can be combined with other locators to effectively locate elements.
List<WebElement> allButtons = driver.findElements(By.tagName(“button”));By Xpath
XPath stands for “XML Path Language”. It is a query language that uses “path-like” syntax and is used for traversing through XML documents. It is used to locate nodes within a document to determine whether they match a pattern or not. It also helps to navigate through the DOM of HTML and to find elements and contains over 200 built-in functions.
XPath uses path expressions (very similar to path expressions in computer file systems) along with some conditions to select nodes or node-sets in an XML document. In XML, there are seven kinds of nodes – element, attribute, text, namespace, processing-instruction, comment and document nodes. The XML documents are treated as nodes and the topmost element of the node is called the “root element”. Each element and attribute has one parent. Element nodes may have zero or more children. “Siblings” are the nodes that have the same parent. “Ancestors” are a node’s parent, parent’s parent etc. “Descendants” are node’s children, children’s children etc. Some common XPath expressions are:
nodename -> Selects all nodes with the name “nodename”
/ -> Selects from the root node or current node
// -> Selects nodes in the document from the current node that match the selection no matter where they are
. -> Selects the current node
.. -> Selects the parent of the current node
@ -> Selects attribute
[] -> Predicates are used to find a specific node or a node that contains a specific value
* , @* , node() -> Wildcards are used to select unknown XML nodes
The XPath syntax is like below:
XPath=//tagname[@attribute=’attribute value’]
where, tagname = a, input, button, form, td, tr, table, select, svg, h1, h2, h3 etc.
attribute = type, class, name, id, placeholder, data-ng-click, value etc.
attribute value = any text or numeric value with/without characters
There are 2 types of XPath – 1) Absolute XPath and 2) Relative XPath
Absolute XPath
The direct way to find the elements is the “Absolute XPath” which starts with root node or with “/”. When we use absolute xpath, it covers the whole path to the element, considering the complete hierarchy in the DOM. The disadvantage is that if there are any changes made in the element path, the element locating will get failed. For the username element in the GitHub page, the absolute xpath will look like:
/html/body/div[4]/main/div[1]/div/div/div[2]/div/form/auto-check[1]/dl/dd/input
and the Java statement to locate the element will look like:
WebElement userName = driver.findElement(By.xpath(“/html/body/div[4]/main/div[1]/div/div/div[2]/div/form/auto-check[1]/dl/dd/input”));
Relative XPath
In this technique, the element can be located directly irrespective of its position in the DOM hierarchy. The path starts from the middle of the HTML DOM structure. It begins with the double forward slash (//) which means that it can search the element anywhere in the webpage. For example, we can locate the same username field in the following way using attribute and attribute value:
WebElement userName = driver.findElement(By.xpath(“//input[@id=’ user[login]’]”));
XPath Functions
Locating a particular element out of many elements on a webpage becomes challenging when all of them have same attributes. In such cases, XPath functions come to the rescue. For Selenium, the most commonly used XPath functions are contains(), starts-with(), ends-with() and text().
contains() – When the value of any attribute changes dynamically, this method can come into use by locating an element with the available partial text.
WebElement userName = driver.findElement(By.xpath(“//input[contains(@id,’ user’)]”));
starts-with() – It is used to locate an element whose attribute value changes on the refresh or on any other dynamic operation on the webpage. Here, we match the starting text of the attribute to locate an element whose attribute has changed dynamically.
WebElement userName = driver.findElement(By.xpath(“//input[starts-with(@id,’ user’)]”));
ends-with() – Similar to starts-with, this is used to locate an element whose attribute value changes on the refresh or on any other dynamic operation on the webpage. Here, we match the closing text of the attribute to locate an element whose attribute has changed dynamically.
WebElement userName = driver.findElement(By.xpath(“//input[ends-with(@id,’ gin]’)]”));
text() – This is used to locate a web element with exact text. If we want to locate the “Terms of Service” link we can use the text() XPath function like below:
WebElement termsOfServiceLink = driver.findElement(By.xpath(“//*[text()=’Terms of Service’]”));
The “@” symbol is not used with text because here text() is a function and not an attribute.
XPath Index
There could be multiple elements in the same webpage matching the specified XPath query. If the element is not the first element, we can also locate the element by using its index/position in DOM. For example in our GitHub home page, we can locate the username text field which is the sixth <input> element on the page in the following way:
WebElement userName = driver.findElement(By.xpath(“//input[6]”));
Locating using multiple attributes with XPath
There might be some cases where a single attribute might not be sufficient to locate an element. In such cases, we need to combine additional attributes for a precise match. Example:
WebElement userName = driver.findElement(By.xpath(“//input[@id=’ user[login]’][@class=’ form-control’]”));
Alternatively, we can also write like below using the XPath “and” operator or XPath “or” operator:
WebElement userName = driver.findElement(By.xpath(“//input[@id=’ user[login]’ and @class=’ form-control’]”));
WebElement userName = driver.findElement(By.xpath(“//input[@id=’ user[login]’ or @class=’ form-control’]”));
Locating using any attribute value
If we want to match the attributes for all the input tag elements for a specific attribute value, we can use the following:
WebElement userName = driver.findElement(By.xpath(“//input[@*=’ user[login]’]”));
Locating elements using XPath axes
We can take the help of XPath axes to locate elements based on their relationship with other elements in the document. Some common XPath axes are ancestor, descendant, following, following-sibling, preceding and preceding-sibling.
ancestor
Locates all ancestors (including parent, grandparent etc.) of the current node
//a[text()=’Terms of Service’]/ancestor::p
descendant
Locates all descendants (including children, grandchildren etc.) of the current node
/table/descendant::td/li/ul/a
following
Locates everything in the document after the closing tag of the current node
//td[text()=’Terms’]/following::tr
following-sibling
Locates all siblings after the current node
//td[text()=’Terms’]/following-sibling::td
preceding
Locates all nodes that appear before the current node in the document (except ancestors, attribute nodes and namespace nodes)
//td[text()=’Terms’]/preceding::tr
preceding-sibling
Locates all siblings before the current node in the document
//td[text()=’Terms’]/preceding-sibling::td
By CSS Selector
CSS stands for “Cascading Style Sheets”. It is a simple design or style sheet language intended to simplify the process of making web pages presentable by handling the look and feel part of a webpage. It is combined with the markup languages like HTML or XHTML. Using CSS, the UI developers control the colors of the web elements, their font styles, spacing, padding, margin, border, size, layout designs etc. Most of the web browsers implement CSS parsing engines for formatting or styling the pages using CSS syntax. In CSS, pattern matching rules determine which style should be applied to elements in the DOM. These patterns are called “Selectors” and may range from simple element names to rich contextual patterns. If all conditions in the pattern are true for an element, then the selector matches that element. By using CSS Selectors in Selenium, we can find or select HTML elements on the basis of their id, class or other attributes. Locating elements using CSS Selector is much faster that using XPath. Selenium WebDriver’s By class provides the cssSelector() method for locating elements using CSS Selectors.
The CSS Selector syntax using Absolute Path is like below:
CSS Selector=tagname1 tagname2 tagname3 …. tagnameN
OR
CSS Selector=tagname1 > tagname2 > tagname3 > …. > tagnameN
The CSS Selector syntax using Relative Path is like below:
CSS Selector=tagname[attribute=’attribute value’]
Notice that unlike XPath, the “//” and “@” symbols are not used here.
Now, consider the below HTML
<dl class="form-group mt-0">
<dt class="input-label">
<label class="form-label h5" for="user[login]">Username</label>
</dt>
<dd>
<input type="text" name="user[login]" id="user[login]" class="form-control form-control-lg input-block">
</dd>
</dl>Here, if we want to locate the username element using CSS Selector, we can use the below Java statement:
WebElement userName = driver.findElement(By.cssSelector(“input[id=’ user[login]’]”));
We can also write the CSS Selector with ID attribute like below (using “#” symbol):
WebElement userName = driver.findElement(By.cssSelector(“input#user[login] “));
To use a single class attribute value we can write like (using “.” symbol):
WebElement userName = driver.findElement(By.cssSelector(“input.form-control”));
To use multiple class attribute values:
WebElement userName = driver.findElement(By.cssSelector(“input.form-control.input-block”));
Sometimes we may come across scenarios where we have to handle dynamically generated attributes or we want to locate elements with substrings. For this, we can follow the below syntax:
Locate with CSS Selector using string starting text
WebElement userName = driver.findElement(By.cssSelector(“input[id^=’user’]”));
Locate with CSS Selector using string ending text
WebElement userName = driver.findElement(By.cssSelector(“input[id$=’gin]’]”));
Locate with CSS Selector using string within text
WebElement userName = driver.findElement(By.cssSelector(“input[class*=’ control-lg’]”));
ACTIONS
For performing Web UI testing, after we locate the elements, we need to perform some actions on those elements. The WebDriver implements a very comprehensive API to work with web elements, user interactions, execute JavaScript code on the webpage and support the various types of controls like checkbox, textbox, radiobutton, button, combobos, lists, links, dropdown etc. Let’s discuss them one by one.
Extracting the element’s text
To extract and verify the text or values from an element, we can use the getText() method provided by the WebDriver API. The extracted actual text/value can be stored in a variable and then compared with the expected text/value. The getText() methods returns the value of the “innerText” attribute of the element. If child elements are present, then it extracts the child elements’ innerText values too and append with the innerText of the parent element.
package tests;
import org.junit.Assert;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class BasicTest {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "./driver/chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get("https://github.com/");
driver.manage().window().maximize();
// Verify element's text
WebElement userNameLabel = driver.findElement(By.cssSelector("label[for='user[login]']"));
Assert.assertEquals("Username", userNameLabel.getText());
}
}Extracting the element’s attribute value and CSS Value
The UI developers add attributes to the web elements and add values to those attributes to control the behavior or style of elements when they are displayed in the web browsers. Sometimes, testers need to extract those attribute values and perform checks with the expected values to test that the attributes are set correctly. For that, we can use the getAttribute() method provided by the WebElement interface.
As told earlier, CSS or Cascading Style Sheets are used in the webpage to improve the look and feel of it. Sometimes, tests may be required to verify that correct styles have been applied to the elements. For that, we can use the getCssValue() method provided by the WebElement interface which returns the value of a specified style attribute in String format. Below code is to extract the value of the “type” attribute and from the username element.
package tests;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class BasicTest {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "./driver/chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get("https://github.com/");
driver.manage().window().maximize();
// Extract element's attribute value
WebElement userNameLabel = driver.findElement(By.id("user[login]"));
System.out.println(userNameLabel.getAttribute("type"));
// Extract value of element's CSS property
System.out.println(userNameLabel.getCssValue("text-align"));
}
}Entering text into textboxes/textarea
Textboxes in the webpage are usually defined by the “input” tag accompanied by the attribute “type” set to the value “text” and for textarea, the attribute “text” is set to the value “textarea”. To enter values to textboxes/ textarea we have to use the sendKeys() method of the RemoteWebElement class which implements the WebElement interface.
package tests;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class BasicTest {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "./driver/chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get("https://github.com/");
driver.manage().window().maximize();
// Enter text value to element
WebElement userNameLabel = driver.findElement(By.id("user[login]"));
userNameLabel.sendKeys("Username1");
}
}Interacting with Buttons, RadioButtons and Checkboxes
For creating buttons in the HTML page, the UI developers either use the “button” tag or “input” tag with the attribute “type” set to “button”. For radiobuttons, the “input” tag is given the attribute “type” set to the value “radio”. For checkboxes, the “input” tag is given the attribute “type” set to the value “checkbox”. We have to use the click() method of the RemoteWebElement class to click on a button, radiobutton or to check/uncheck a checkbox. Remember that clicking on an unchecked checkbox makes it “checked” and clicking on a checked checkbox makes it “unchecked”.
package tests;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class BasicTest {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "./driver/chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get("https://github.com/");
driver.manage().window().maximize();
// Clicking on a button element
WebElement signUpButton = driver.findElement(By.xpath("(//button[@type='submit'])[1]"));
signUpButton.click();
// Selecting a radiobutton element
WebElement genderRadioButton = driver.findElement(By.xpath("//input[@type='radio']"));
genderRadioButton.click();
// Checking/ Unchecking a checkbox element
WebElement subscribeCheckBox = driver.findElement(By.xpath("//input[@type='checkbox']"));
subscribeCheckBox.click();
}
}Interacting with Dropdowns and Lists
Selenium WebDriver API supports interaction with Dropdowns and Lists using a special “Select” class which implements two interfaces “ISelect” and “WrapsElement”. The “Select” class provides various methods and properties to interact with dropdown and list elements created with the HTML <select> tag which supports multi-select options. The Select class provides 3 different ways to select/deselect the options from dropdowns and lists. We can select an option by its visible text,its value and its index (that is, its position).
Capturing Screenshots
Selenium WebDriver API provides the “TakesScreenshot” interface to capture a screenshot of the webpage under test. This helps to capture exactly what happened during the test or whether an exception/ error occurred during the test execution. We can also capture screenshots during verification of the element state, the displayed values, state after user interaction is complete, layouts, field alignments etc. The “TakesScreenshot” interface provides the getScreenshotAs() method to capture screenshot displayed in the driver instance. In the below example, we specified OutputType.FILE as an argument to the method which will return the captured screenshot and save it in a new PNG file (using the copyFile method of FileUtils class) inside the “screenshots” folder created in the FirstSeleniumTest project. Note that you have to add commons.io jar separately to the project to use this functionality.
package tests;
import java.io.File;
import org.apache.commons.io.FileUtils;
import org.openqa.selenium.By;
import org.openqa.selenium.OutputType;
import org.openqa.selenium.TakesScreenshot;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.Select;
public class BasicTest {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "./driver/chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get("http://www.echoecho.com/htmlforms11.htm");
driver.manage().window().maximize();
// Selecting from dropdown menu
WebElement dropdownList = driver.findElement(By.name("dropdownmenu"));
Select select = new Select(dropdownList);
select.selectByIndex(2);
select.selectByVisibleText("Cheese");
select.selectByValue("Butter");
// Taking Screenshot
try {
TakesScreenshot tk = (TakesScreenshot) driver;
File screenshotFile = tk.getScreenshotAs(OutputType.FILE);
FileUtils.copyFile(screenshotFile, new File("./screenshots/Screenshot1.png"));
} catch (Exception e) {
e.printStackTrace();
}
}
}Using JavaScript
The Selenium WebDriver API provides functionality to execute the JavaScript code on the browser which is very useful while the tests need to interact with the webpage using JavaScript only. The API provides the “JavascriptExecutor” interface which can be used to JavaScript code within the browser context.
package tests;
import org.junit.Assert;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class BasicTest {
public static void main(String[] args) {
System.setProperty("webdriver.chrome.driver", "./driver/chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get("https://www.google.com");
driver.manage().window().maximize();
// Executing JavaScript
JavascriptExecutor js = (JavascriptExecutor) driver;
String title = (String) js.executeScript("return document.title");
Assert.assertEquals("Google", title);
}
}Credits:
https://www.selenium.dev/