Machine Learning (popularly known as ML) is the study of different Algorithms and Statistical Models (using data) which can be used by computer systems to perform/ predict/ decide/ improve on specific tasks efficiently by relying on patterns and inference from the study of the collected data (without taking help of explicit instructions). It can be considered as a subset of Artificial Intelligence which covers a broader scope.
The Machine Learning Algorithms build mathematical models based on collected sample data (known as Training Data) and come up with predictions/decisions without being explicitly programmed by humans (like what usually happens in traditional programming sphere) to perform the task. ML is closely related to Computational Statistics field which focuses on making predictions using computers. The study of mathematical optimization delivers methods, theory and application domains to the field of ML.
There is a lot of hype in using the terms Machine Learning, Artificial Intelligence, Data Science, Predictive Analytics and Deep Learning and people tend to use these terms interchangeably. Though the boundaries between these terms are not well-defined and debatable, let’s try to understand the basic differences between them from the image below:
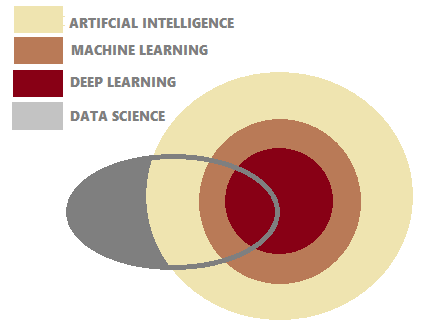
AI is the idea that came first – the largest set, then came ML – a subset of AI which blossomed later and finally Deep Learning (DL), a subset of ML, which is driving today’s AI explosion. Data Science is a multi-disciplinary field which intersects the fields of AI, Machine Learning and Deep Learning.
ARTIFICIAL INTELLIGENCE (Machines exhibiting Human Intelligence)
Artificial Intelligence, in general, is the part of Computer Science concerned with designing of Intelligent Computer Systems which exhibit characteristics of human-level intelligence. The origin of the field of ‘AI’ can be traced back to 1956 when a handful of computer scientists rallied around the term at the Dartmouth Conferences. Over the last few years AI has exploded and much of that has to do with the wide availability of GPUs that make parallel processing faster, cheaper and powerful, infinite storage capabilities and availability of lots and lots of data. Based on capabilities, AI can be classified into following 3 types:-
- Weak (Narrow) AI – Type of AI which is able to perform a dedicated task with Intelligence. Most common and currently available AI today falls in this category.
- General AI – Type of AI which could perform any intellectual task with efficiency like a human. At present, no such system come under this category.
- Super AI – Type of AI with which machines can surpass human intelligence and can perform any task better than human with cognitive properties.
MACHINE LEARNING (An approach to achieve AI)
Machine Learning is the practice of using Algorithms and Statistical Models to cleanse and parse data, learn from it and then make prediction/ decision about something in the world. So, rather than programming a software explicitly to perform a particular task, the machine is trained with large amounts of data that gives it ability to learn how to perform the task. Machine Learning can be considered as an approach to achieve Artificial Intelligence.
DEEP LEARNING (A technique to perform Machine Learning)
Deep Learning is a subset of Machine Learning and is based on the concepts of Neural Networks. Neural Networks are inspired by our understanding of the human brain biology which is driven by the neurons and the interconnection between them. But, unlike a biological brain where any neuron can connect to any other neuron within a certain physical distance, the Neural Networks in Deep Learning have discrete layers, connections and directions of data propagation.
DATA SCIENCE
Data Science, in general, is a multi-disciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured/ unstructured data. It employs techniques and theories drawn from many fields within the context of Mathematics, Statistics, Computer Science and Information Science. Data Science covers concepts like Probability, Statistics, Linear Algebra, Matrix Algebra, Numerical Optimization etc. to help the Machine Learning and Deep Learning algorithms to come up with solutions in the AI space.
TYPES OF MACHINE LEARNING
Machine Learning is mainly classified into three types:-
- Supervised Learning (“The model says – Please Train me”)
- Unsupervised Learning (“The model says – I am self-sufficient to learn myself”)
- Reinforcement Learning (“The model says – I will decide the rule – Hit and Trial”)
Supervised Learning
In Supervised Learning, the machine learning model is given a labeled dataset and we already know what the correct output should look like, having the idea that there is a “relationship between the input and the output”. The dataset acts like a trainer to the model. Once the model gets trained, it can start making predictions and the prediction results act as a feedback to the model to make the future predictions more accurate.
Supervised Learning is further classified into 1) Regression and 2) Classification problems.
In Regression, the model tries to predict the result within a continuous output, which means that, we try to map the input variables to some continuous function.
In Classification, the model tries to predict the result within a discrete output, which means that, we try to map the input variables to some discrete category.
Unsupervised Learning
In Unsupervised Learning, the machine learning model is not given any dataset to get trained (no training data) and it “learns through observation and finds structures in the data”. It allows us to approach problems with little or no knowledge what our results should look like. We can derive structure from data where we don’t necessarily know the effect of the features or variables. We can derive this structure by clustering the data based on relationships among the variables in the data. With unsupervised learning, there is no feedback to the model based on the prediction results. Practical examples include Social Network Analysis, Market Segmentation of Customers, Organizing Computing clusters, Astronomical Data Analysis etc.
Reinforcement Learning
Reinforcement Learning is the ability of a model to interact with the environment and find out what is the best outcome. It follows the concept of Hit and Trial Method. The model is Rewarded or Penalized with a point for a correct or wrong answer respectively. On the basis of positive reward points gained, the model trains itself. Once trained, again the model gets ready to predict the new data presented to it.
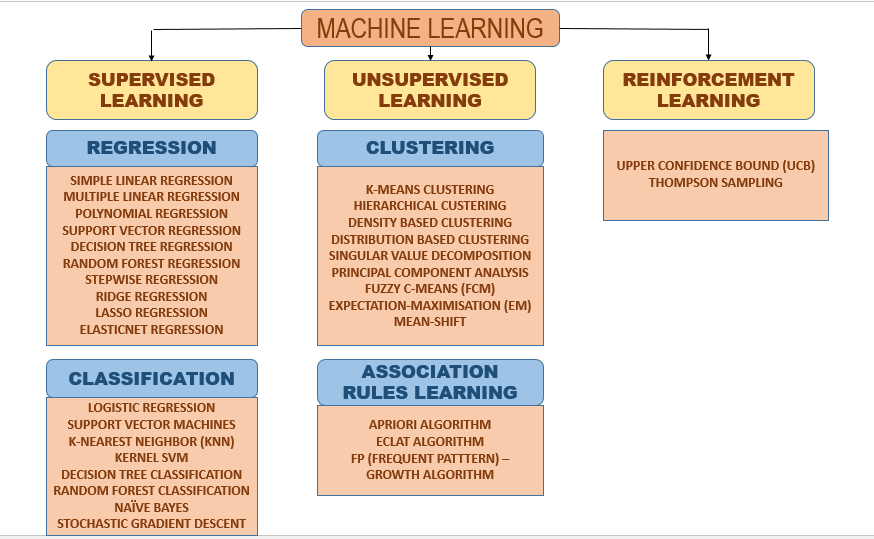
Below is a diagram which shows the different types of Machine Learning algorithms and their classification: